こんにちは。FLINTERS BASE 開発部 小杉です。
早いもので、配属されてから7ヶ月、入社してから10ヶ月が経ちました。ようやく自社ドメインの知識が増えてきてエンジニアという仕事に慣れつつあります。(まだまだポンコツの域を抜けませんが、、、)
今回は以前から整理したいなと思っていたメタデータをテーマに書いていきたいと思います!
(ちなみに以前データモデルに関する記事も書いてみているので興味があれば是非読んでみてください)
モチベーション
最近自組織のデータの流れが見えるようになってきた中で、「このバッチ処理がなんでエラーを起こしているんだろう?」とか「このテーブル消したら他のどこに影響が出るんだろうか」などと考える機会が多くあります。
その時にふと思ったのが、「やっぱりデータがちゃんと整理されていると、きちんと根拠を持って意思決定を行えるな」ということです。
ただ、感謝すべきことに配属先は「データを整備する」ということを既に組織単位で実行できているので、自分で改めてどういう観点でデータを管理、整理すれば良いのかというのを捉え直したいという意味で今回のテーマを選択しました。
事前準備
今回は気軽に試してみたかったので、Open Metadataと呼ばれるOSSのデータカタログツールを使用しました。環境構築に関してはDockerまたはSandboxを使用して簡単にできるのでそちらを参考にしてみてください。
今回はよりSampleデータが見やすいSandboxを使用します。
メタデータとは
今回はメタデータの種類ごとにOpen Metadataの機能に着目して感想を書こうと思うので、先にメタデータについて簡単に説明します。(もう既に知っているという方は次のセクションに進んでください)
そもそもメタデータとは、
データを表すデータ
のことを指します。その上で更に以下の3種類に分けることができます。
それぞれもう少し具体的に説明をしていきます。
ビジネスメタデータ
ビジネスメタデータとは、業務に関するメタデータを指します。例を挙げると、
- テーブル定義
- データの意味の説明、関連性
- 業務ルールやドメイン知識
などになります。
テクニカルメタデータ
テクニカルメタデータとは、技術的な内容に関するメタデータを指します。例を挙げると、
- テーブルの抽出条件
- リネージュとプロバナンス(テーブルの紐付きや取得元など)
- テーブルの形式やロケーション
- アクセス権
- テーブルの生成情報
などになります。
オペレーショナルメタデータ
オペレーショナルメタデータとは、データの処理やアクセスに関するメタデータを指します。例を挙げると、
- テーブルステータス
- メタデータの更新日時
- バッチプログラムの実行ログ
- 1ファイルのデータサイズ
などになります。
今回はこの3種類の観点で切り分けながら、Open Metadataを触り「データを管理する」ということについて普段感じていることを踏まえて書いていきたいと思います!
Open Metadataを触りながらデータを管理する意味について考える
今回は以下のテーブル情報を参考に見ていきます。
- DB:ecommerce_db
- Schema : shopify
- Table : dim customer
ビジネスメタデータの観点
まずはビジネスメタデータの観点から、普段頻繁にチェックしているなと感じるポイントは2つです。
- Point ①:データの所有者
- Point ②:このテーブルはなんなのか
一つ目に関しては、Open Metadataだと一目で把握できますね。データに関しての問い合わせやアクセス権が欲しいとなった場合にデータの所有者がすぐに把握できればコミュニケーションコストを大きく削減できます。

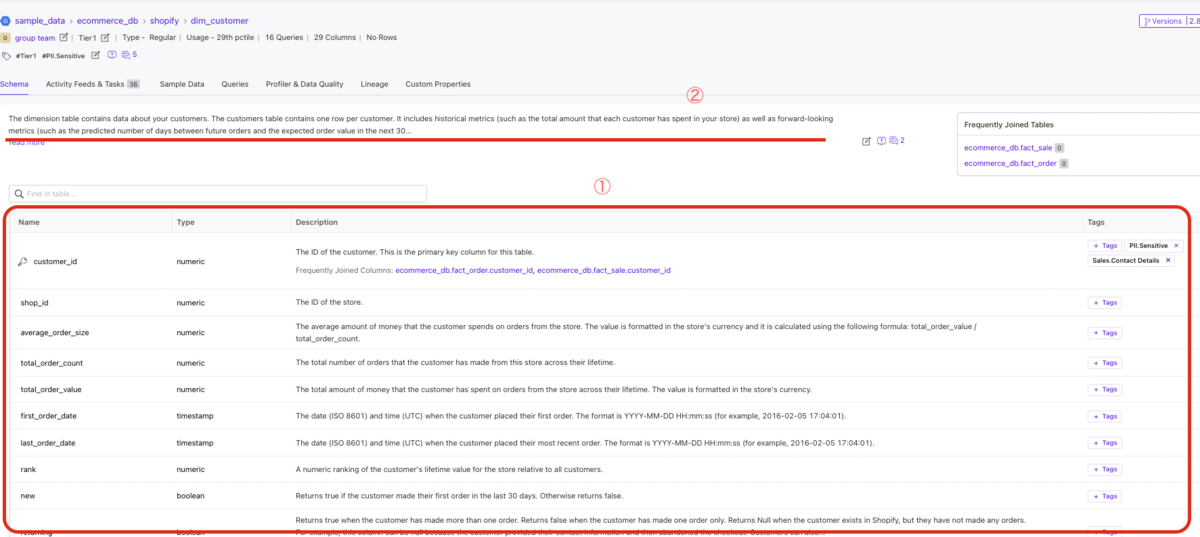
二つ目に関しては、下記画像から
- ①データ(各カラム)の詳細
- ②テーブルの説明
がわかると思います。勿論クエリを叩けばテーブルスキーマなどは確認できるのですが、GUIで確認できることでエンジニアとアナリストなどの情報のギャップが少なくなります。
特にテーブルの削除対応等をしたりする時に、「何のために作られたテーブルなんだ?」という事態がなくなるので、色んなwikiの中を彷徨うことがなくなります。
テクニカルメタデータの観点
次はテクニカルメタデータの観点から見てみましょう。上述したテクニカルメタデータの例はどれも大事なのですが、個人的には以下の2点がエンジニアとしてよくチェックする情報かなと思います。
- Point ①:データの生成状況
- Point ②:リネージュとプロバナンス(テーブルの紐付きや取得元など)
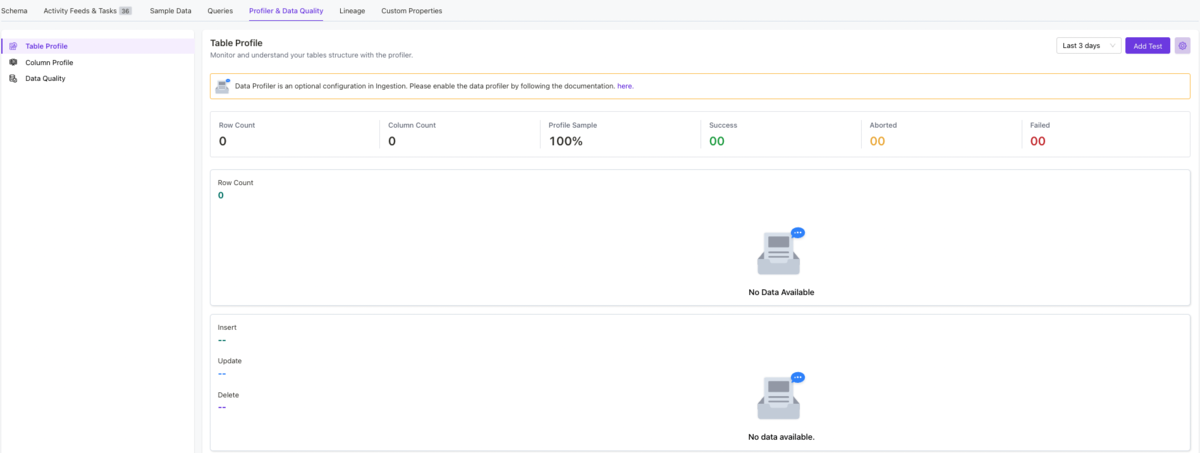
①はSampleデータなので表示されていませんが、直近のテーブル生成状況が確認できそうです。(実際にProfilerを使って今度試してみたい)
ここでは、その日のデータがきちんと生成されたかどうかを確認する時に役立ちます。データに欠損があるか、そもそもテーブル自体が生成されていないのかとかとか。
②個人的にはこの機能が普段一番役に立っていると思います!(Open Metadataはもう少しわかりやすく表示して欲しい気もしますが、、、)
リネージュはこのdim_customerというテーブルがどのテーブルを組み合わせてデータを取得しているか、またこのテーブルが他のどのテーブルから参照されているかを把握できる機能です。データを管理する上で、一つ一つのテーブルについてだけではなく、その関連性が簡単に分かるのでこのテーブルの影響度やエラーの原因把握に効力を発揮します。

オペレーショナルメタデータの観点
最後はオペレーショナルメタデータの観点から見ていきます。
ここは地味な部分ですが、以下が大事な観点かなと思っています。
- Point ①:テーブルのステータス
- Point ②:メタデータのアップデート状況
この観点に関しては少しビジネス側のユーザー視点で書いてみました。実際にテーブルを使う側からすると、「現在このテーブルが使えるの?使えないの?」という点はすぐに把握したいものです。Open Metadataでは先ほどのProfilerから確認ができます。
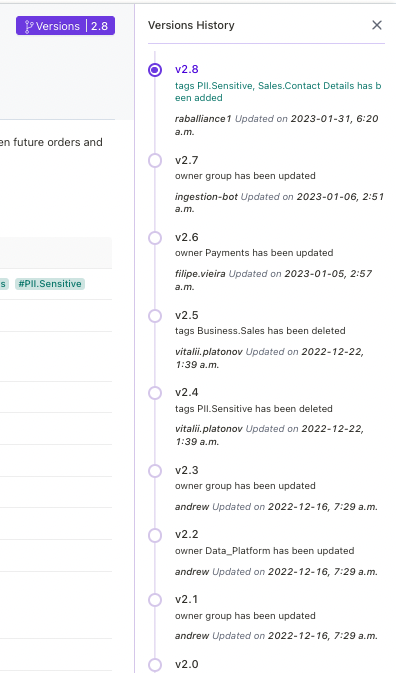
また②に関してはテーブルの所有者を先頭に常に心がけていきたい観点だと思います。
実際にバージョンヒストリーでも確認できますが、関連するwikiやディスクリプションをアップデートすることで認識の齟齬を減らせます。
まとめ
実際に使ってみて、Open Metadataの機能めっちゃ充実してるやん!と感じました。ただ、じゃあとりあえず導入すればいけるかということではなく、言うが易しな部分はどうしても否めません。
今回改めてここがメリットだなということについては整理できたので、もう少し全体俯瞰をしながら、「どのユーザーにとってはどういうことがプラスなのか?」「仮にデータの管理ができていない組織に導入するとしたらどう浸透させていくか」などを少しずつ考えてみたいなと思います。
(次回はもっと自分でデータを使いながら試してみたい、、、)
読んでいただきありがとうございました🙇
参考文献
メタデータに関しての記載は以下を参考にいたしました。
その他参考文献